
Wyobraź sobie, że spacerujesz po plaży i zauważasz na piasku napis: „Romeo kocha Julię”. Większość z nas widziała napisy na piasku i nie ma w tym nic zaskakującego. Jednak zobaczenie całego tekstu dramatu Williama Szekspira „Romeo i Julia” zapisanego na piasku byłoby dla każdego z nas ogromnym zaskoczeniem. Dlaczego? Oczywistym powodem jest to, że piasek nie jest odpowiednim materiałem, na którym można zapisać długi tekst. Ziarna piasku łatwo się poruszają (np. pod wpływem wiatru), a tekst na nim zapisany szybko się zaciera (ryc. 1). Zanim pierwszy akt dramatu „Romeo i Julia” zostałby całkowicie zapisany na piasku, początek tekstu zniknąłby za sprawą wiejącego wiatru lub fal omywających plażę.

Z drugiej strony nie dziwi fakt, że sztuka „Romeo i Julia” została spisana na papierze. Papier jest materiałem zwartym i może przetrwać wiele lat, tym samym jest doskonałym materiałem do zapisywania i przechowywania informacji. Moglibyśmy wspomnieć również o innych nośnikach wykorzystywanych przez ludzi do zapisywania informacji, ponieważ na przestrzeni historii ludzie stosowali różne materiały – od skał po pergamin ze skór owczych – jednak tani, otrzymywany w dużych ilościach, stosunkowo trwały papier okazał się jednym z najlepszych materiałów do zapisywania i przechowywania informacji, jaki kiedykolwiek wymyślono.
DNA – stabilny nośnik do przechowywania informacji genetycznej
Wewnątrz komórek znajdujemy nośnik przechowujący informację, który – podobnie jak papier – wydaje się być najodpowiedniejszym materiałem do przechowywania informacji genetycznej. Nazywamy go kwasem dezoksyrybonukleinowym lub w skrócie DNA.
Jednym z powodów, dla których DNA jest doskonałym materiałem do przechowywania danych genetycznych, jest jego niesamowita stabilność chemiczna. DNA może przetrwać tysiące lat po śmierci organizmu, co pozwoliło nam odczytać DNA dawno wymarłych organizmów, od naszych neandertalskich krewnych1 po włochate mamuty2. Stabilność chemiczna jest niezbędna do prawidłowego funkcjonowania DNA jako nośnika informacji. Gdyby był niestabilny, kodowane przez niego informacje ulegałyby szybkiej degradacji – podobnie jak informacje zapisane na piasku.
DNA – wydajny nośnik przechowywania informacji
Nasze własne DNA ilustruje inną istotną cechę DNA. Ludzki genom obejmujący całe nasze DNA upakowany jest w 23 ludzkich chromosomach – dwie kopie każdego chromosomu znajdują się w większości komórek3, a także w DNA mitochondrialnym. DNA przechowuje informacje znacznie wydajniej niż słowa drukowane na papierze. Na przykład ludzki mitochondrialny DNA ma tylko około 5,6 μm długości – tj. około jednej setnej średnicy kropki stawianej na końcu zdania – ale zawarta w nim informacja wydrukowa na papierze jako litery odzwierciedlające sekwencję DNA zajmuje około 6 stron. Natomiast cały ludzki genom ma około metra długości i aby „wydrukować” całą zawartą w nim informację, musielibyśmy poświęcić na to około milion stron! Oczywiście milion stron nie zmieści się w komórce, ale cała ta informacja zmieści się w maleńkim jądrze komórki, jeśli jest zakodowana w DNA. Zdolność DNA do przechowywania informacji w niewielkiej przestrzeni czyni go najbardziej wydajnym nośnikiem informacji – w kontekście gęstości informacji – jaki znamy.
DNA – nośnik informacji, który można dokładnie skopiować
Podwójnie helikalna struktura DNA również w zadziwiający sposób przyczynia się do spełniania przez niego funkcji nośnika informacji. Kiedy większość komórek dzieli się, konieczne jest wykonanie pełnej kopii DNA w komórce „macierzystej”, aby każda komórka „córka” otrzymała jedną kompletną kopię DNA komórki macierzystej. Informacja kodowana jest w DNA przy użyciu sekwencji związków chemicznych zwanych zasadami nukleotydowymi. Zasady te są analogiczne do liter, których używamy do przeliterowania informacji, a pełna kopia ludzkiego genomu zawiera około 3 miliardów zasad. Kiedy komórki ludzkie dzielą się, wyzwaniem jest dokładne skopiowanie 6 miliardów zasad, ponieważ każda komórka macierzysta zawiera dwie kopie ludzkiego genomu.
Życie ludzkie rozpoczyna się w momencie zapłodnienia pojedynczej komórki jajowej, która dzieli się, a kolejne podziały następują do momentu, aż organizm osiągnie „dorosłą” liczbę komórek, czyli około 37 bilionów4. Będąc dorosłymi, nasze komórki nadal dzielą się i rosną, ponieważ tracimy stare komórki, które muszą być zastąpione nowymi. Tak więc każdego dnia miliony komórek dzielą się w naszym ciele, co oznacza, że miliony kopii 6 miliardów zasad DNA każdej komórki muszą zostać dokładnie skopiowane. Chociaż liczba powielań DNA oraz długość 3 miliardów zasad ludzkiego genomu mogą wydawać się imponujące, nie jest to wyjątkowe. Wiele innych organizmów, od kukurydzy po niektóre salamandry, ma znacznie większe genomy. Największym znanym zwierzęcym genomem jest genom prapłetwca abisyńskiego, Protopterus aethiopicus, posiadający 139 miliardów zasad w genomie, ale znane są organizmy o jeszcze większych genomach5.
Kiedy w 1953 r. James Watson i Francis Crick opublikowali swój przełomowy artykuł6, ujawniając światu podwójną helikalną strukturę DNA, natychmiast zauważyli, że struktura ta sugeruje mechanizm precyzyjnej replikacji DNA:
„Nie umknęło naszej uwadze, że postulowane przez nas specyficzne parowanie sugeruje jednocześnie możliwy mechanizm kopiowania materiału genetycznego”.
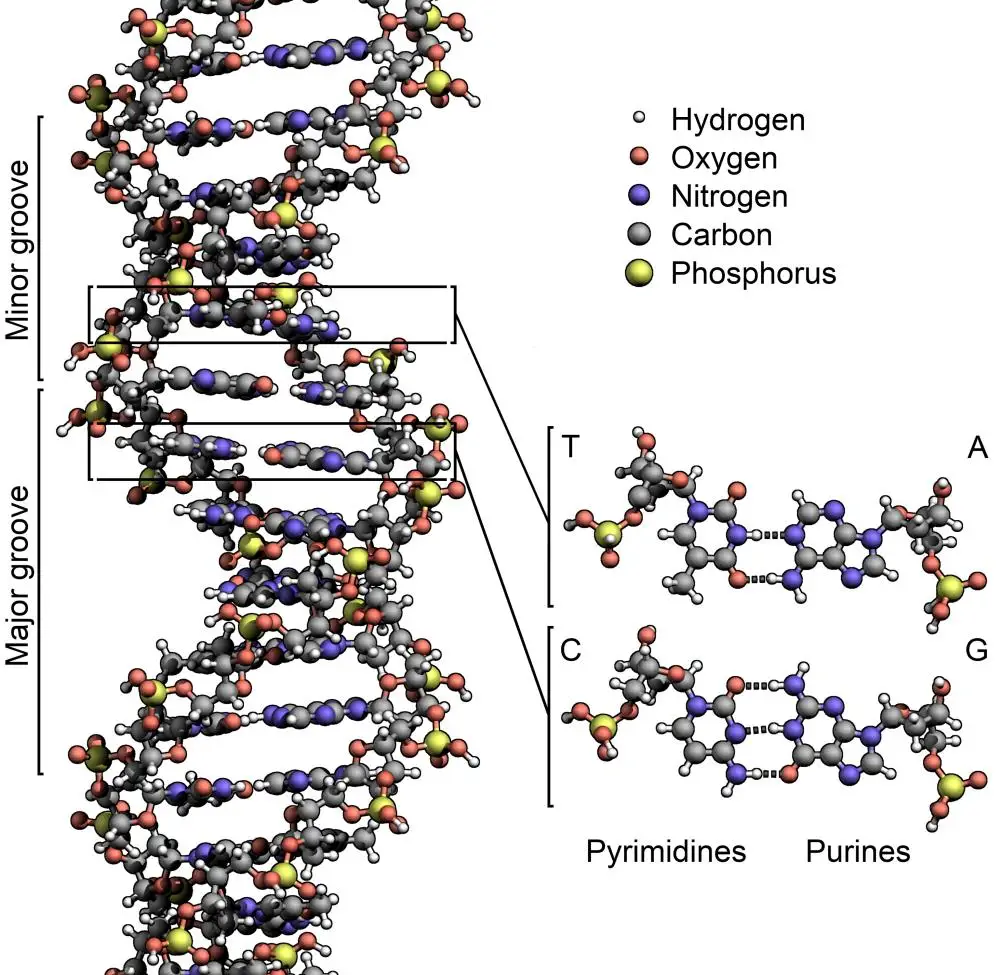
Parowanie (komplementarność–przyp.tłum.), do którego odnoszą się Watson i Crick, dotyczy zasad nukleotydowych będących, jak już wcześniej wspomniano, „literami” alfabetu DNA. Zasady są płaskimi cząsteczkami przyłączonymi do dwóch nici podwójnej helisy. Dwie nici podwójnej helisy oplatają wspólną oś, a ich zasady skierowane są do wnętrza helisy i oddziałują ze sobą w bardzo specyficzny sposób. Zasady można podzielić na dwie klasy: zasady purynowe – adenina (A) i guanina (G), których cząsteczki są stosunkowo duże oraz zasady pirymidynowe – tymina (T) i cytozyna (C), które są mniejsze. Ponadto ładunki na powierzchni tych zasad rozmieszczone są w różny sposób. Z tego powodu, jak również z powodu geometrii DNA – w którym zasady skierowane są ku sobie we wnętrzu helisy – adenina (A) na jednej nici podwójnej helisy łączy się zawsze z tyminą (T) na przeciwnej nici i odwrotnie. To samo dotyczy guaniny (G) i cytozyny (C). Jeśli zatem na jednej nici podwójnej helisy znajduje się zasada A, możesz być pewny, że na przeciwnej nici znajduje się zasada T, a jeśli na jednej nici masz C, to z pewnością na przeciwnej nici będzie G.
Jeśli podwójna helisa zostanie rozpleciona, to uzyskamy pojedyncze nici DNA, a każda nić jest ujemną kopią przeciwnej nici. Tak więc w procesie replikacji DNA podwójna helisa DNA ulega rozpleceniu, a każda nić służy jako szablon do wykonania dokładnej kopii drugiej nici. Oczywiście istnieje złożona maszyneria komórkowa, która sprawia, że tak się dzieje, ale jeśli jedna nić ma sekwencję AGTCCGC, to przeciwną nić można z niej dokładnie zrekonstruować jako TCAGGCG7. A zatem struktura DNA przyczynia się do działania niesamowitego sposobu, w jaki można go replikować z niepojętą szybkością i dokładnością.
Pochodzenie DNA jako materiału genetycznego organizmów
Im więcej dowiadujemy się o DNA, tym bardziej wydaje się on być odpowiedni do roli nośnika informacji w komórkach. Wspomnieliśmy już o trzech idealnych cechach nośnika informacji, jakie wykazuje DNA:
- jest stabilny chemicznie, a zatem przechowywana w nim informacja nie ulega degradacji;
- informacja w DNA jest niesamowicie upakowana – przechowywane są ogromne ilości informacji w niewiarygodnie małej objętości;
- struktura DNA umożliwia dokładne kopiowanie informacji ze zdumiewającą prędkością, co jest konieczne podczas szybkich podziałów komórek.
DNA wykazuje również inne cechy, które czynią go idealnym nośnikiem informacji, lecz wyjaśnienie tych zagadnień wiązałoby się z koniecznością przedstawienia szerokiej szczegółowej wiedzy, podczas gdy trzy wyżej przedstawione cechy DNA jako nośnika informacji genetycznej są wystarczające, aby zilustrować omawianą kwestię. Mogą istnieć inne materiały, które mogłyby spełniać taką funkcję jak DNA, ale nie jest znany żaden, który spełniałyby wszystkie wymagania materiału genetycznego tak jak DNA.
Rodzi to pytanie, w jaki sposób organizmy zaczęły ostatecznie używać DNA zamiast jakiejś gorszej cząsteczki w celu przechowywania informacji genetycznej. Dla osób o otwartych umysłach istnieją co najmniej dwie możliwości: albo DNA zostało wybrane jako materiał genetyczny przez kogoś, kto wiedział, jakie cechy posiada DNA, albo DNA zostało wybrane jako materiał genetyczny przez coś, co nie wiedziało nic o jego właściwościach. Ta ostatnia możliwość to materialistyczna wiara w darwinizm. Jak to mogło się wydarzyć? Biorąc pod uwagę zdumiewające dopasowanie pomiędzy właściwościami DNA i jego funkcją oraz zróżnicowanie cząsteczek tworzonych przez organizm, bardzo trudno jest wyobrazić sobie, jak natura wpadła na to rozwiązanie za pierwszym razem. Coś musiało być początkowym materiałem genetycznym, a następnie wypróbowywano różne inne rozwiązania na potrzeby materiału genetycznego, dopóki naturalna selekcja nie zatrzymała się na zasadniczo idealnym rozwiązaniu czyli DNA.
Istnieje jednak znaczny problem z tym darwinowskim scenariuszem. Darwin wskazał, że aby zaproponowany przez niego mechanizm zadziałał, musi on przejść przez „liczne, kolejne, niewielkie modyfikacje”8. Jednak zmieniając materiał genetyczny, nawet przy stosunkowo niewielkich zmianach chemicznych w jego cząsteczkach, nie jest możliwe – z perspektywy organizmu – uzyskanie jakiejkolwiek niewielkiej zmiany. Analogią może być próba zamiany twardego dysku komputera na papier lub informacje wykute w skale. Na twardych dyskach informacje przechowywane są w postaci różnych stanów magnetycznych, sprzęt do ich odczytu musi pasować do nośnika, na którym informacja jest przechowywana. Zatem głowice, które odczytują zmiany stanu magnetycznego na twardym dysku, nie są w stanie odczytać atramentu na papierze lub liter wykutych w kamieniu. To samo dotyczy sprzętu używanego przez komórki do odczytywania informacji z materiału genetycznego. Dzisiaj możemy zbadać maszynerię znajdującą się w komórkach i zobaczyć, że nie możemy zastąpić DNA inną cząsteczką. Cząsteczki takie jak polisacharydy, trójglicerydy lub białka – wszystkie naturalnie wytwarzane w komórkach – nie są szczególnie dobrymi nośnikami do przechowywania informacji, a nawet gdyby były, to nie są odczytywane przez maszynerię odczytującą DNA.
Darwin wskazał, że aby zaproponowany przez niego mechanizm zadziałał, musi on przejść przez „liczne, kolejne, niewielkie modyfikacje”, jednak zmieniając materiał genetyczny, nawet przy stosunkowo niewielkich zmianach chemicznych w jego cząsteczkach, nie jest możliwe – z perspektywy organizmu – uzyskanie jakiejkolwiek niewielkiej zmiany
Widzimy również, że urządzenia zdolne do odczytu różnych nośników są złożonym wyzwaniem inżynieryjnym, ale stworzenie urządzenia wystarczająco elastycznego do odczytu wielu nośników informacji jest trudniejsze o rząd wielkości. Właśnie dlatego, kiedy dokonano przejścia z napędów optycznych na napędy USB, nie podjęto próby stworzenia systemów, które czytają oba – odczytywane są przez różne urządzenia wewnątrz komputerów. Aby przejść do scenariusza materialistycznego obejmującego wiele materiałów genetycznych, potrzebne są mechanizmy odczytu przechowywanych informacji na różnych nośnikach, które w jakiś sposób przewidują potrzebę ich odczytania przed użyciem. W rzeczywistości próba przełączenia komórki na odczyt z jednego materiału genetycznego na inny – nawet jeśli przełączenie dokonuje się pomiędzy materiałem genetycznym o cząsteczkach nieznacznie zmodyfikowanych chemicznie i blisko spokrewnionych – wymaga skoordynowanej zmiany w kilku wewnątrzkomórkowych maszynach molekularnych, co wydaje się dość niezwykłe również w każdym innym systemie, nie mówiąc już o systemie, który nie jest w żaden sposób sterowany.
Alternatywną teorię, że DNA został wybrany jako materiał genetyczny przez kogoś, kto wiedział, jakie właściwości posiada DNA, można porównać z naszym normalnym doświadczeniem. Jedną z pierwszych rzeczy, na które inżynierowie patrzą, gdy pojawia się problem inżynieryjny, są dostępne materiały i podejmowana jest decyzja, które z materiałów najlepiej wykorzystać, aby rozwiązać problem, z którym się zetknęli. Na przykład, projektując silnik samochodowy, inżynier musi użyć materiałów, które będą w stanie wytrzymać ciepło i obciążenia mechaniczne wewnątrz silnika. Woda nie jest odpowiednim materiałem na blok silnika, drewno i beton też nie. Jednak niektóre metale bardzo dobrze nadają się do tego celu, dlatego metale te są najczęściej używanymi materiałami, z których wykonywany jest blok silnika. Inżynierowie znają specyfikacje opracowywanego projektu oraz specyfikacje dostępnych materiałów. Następnie dopasowują materiał wykazujący niezbędne właściwości do danego projektu. Ta obserwacja dobrze pasuje do naszego rozumienia DNA jako materiału genetycznego. Jest to dobrze wyjaśnione w paradygmacie mądrego Projektanta, który wybrał idealny materiał do przechowywania informacji genetycznej w stworzonych przez siebie organizmach. Zadowolony z tego wyboru i wielu innych mógł w ten sposób po zakończeniu swego stworzenia oświadczyć, że było ono „bardzo dobre”9.
Obecność DNA jako materiału genetycznego obecnego w żywych organizmach wskazuje w oczywisty sposób na projekt, ale co z informacjami zakodowanymi w DNA? Chrześcijanie wierzą, że Bóg stworzył żywe stworzenia i jest jedynym źródłem informacji zawartej w genomach. Natomiast najbardziej rozpowszechniona alternatywna teoria pochodzenia żywych organizmów – materialistyczny darwinizm – przypisuje powstanie informacji zawartej w genomie przypadkowym mutacjom i prawom natury, w szczególności selekcji naturalnej. Spójrzmy na dwie cechy genomów, które rzucają światło na ich pochodzenie, a ostatecznie na pochodzenie życia.
Czy większość informacji zakodowanej w DNA to w rzeczywistości śmieci?
Nasze zrozumienie genomów zostało zahamowane przez pośpieszne stwierdzenie, że większość sekwencji genomu to niezawierające informacji „śmieci”10. Susumu Ohno, który ukuł termin „śmieciowe DNA”, elegancko wyraził darwinowski punkt widzenia:
„Ziemia usiana jest kopalnymi szczątkami wymarłych gatunków; czy to dziwne, że nasz genom również jest pełen pozostałości wymarłych genów?”11
Znaczna część DNA nie koduje białek i wielu biologów początkowo zakładało, że wobec tego te niekodujące sekwencje DNA nie pełnią żadnej funkcji. Ten sposób rozumowania prowadził do konkluzji: „jeśli nie wiemy do czego coś służy, to widocznie nie służy niczemu”. Jednakże obecnie wiele danych pokazuje, że logika ta prowadzi do fałszywego wniosku, ponieważ niekodujące sekwencje DNA często pełnią ważne funkcje. To nowe spojrzenie zrewolucjonizowało sposób, w jaki biologowie postrzegają genomy. Zamiast ogromnych pustyń z okazjonalnymi oazami funkcjonalnej informacji, genomy wyglądają bardziej jak informacyjna dżungla z olśniewającą gamą genów, mechanizmów kontrolnych i obwodów logicznych.
Geny są sprytniejsze niż myśleliśmy
Zgodnie z modelem „jeden gen, jeden enzym” zaproponowanym przez Beadle i Tatum (za który zdobyli Nagrodę Nobla), każdy gen koduje pojedyncze białko. Jednak obecnie wszystko się zmieniło. Aktualne szacunki wskazują, że ludzie mają mniej niż 25 000 genów, ale produkują ponad 100 000 białek12, dlatego przynajmniej niektóre geny muszą kodować informację o wielu białkach.
Jak to możliwe?
Spróbujmy to wyjaśnić na przykładzie ludzkiego genu czynnika transkrypcji 2 (ang.: Pituitary Homeobox2) nazywanego w skrócie PITX2. Przykład ten ukazuje, w jaki sposób przetwarzanie RNA może prowadzić do powstania kilku różnych białek z jednego genu. Białko PITX2 (homeodomena PITX2–przyp.tłum.) (ryc. 3) to czynnik transkrypcyjny występujący w rozwijających się tkankach zarodków kręgowców i odgrywa ważną rolę między innymi w rozwoju głowy i oczu13.
Gen PITX2 zawiera sześć segmentów zwanych eksonami (fragmenty DNA, które kodują części białka–przyp.tłum.) oddzielonych pięcioma intronami (fragmenty DNA niekodujące białek i wcześniej uznawane za DNA nie przenoszące żadnej informacji–przyp.tłum.).
Kiedy DNA kodujący gen białka PITX2 jest „przepisany” na RNA (kwas rybonukleinowy bezpośrednio wykorzystywany przez maszynerię komórkową do produkcji białka) można go przetwarzać na różne sposoby w celu wyprodukowania różnych białek. W wyniku połączenia eksonów 1, 2, 5 i 6, powstaje mRNA (informacyjny RNA–przyp.tłum.) dla wersji białka PITX2 o nazwie „Izoforma A” lub w skrócie: PITX2A. Natomiast łączenie eksonów 1, 2, 3, 5 i 6 tworzy mRNA dla białka PITX2B, a eksony 4, 5 i 6 tworzą mRNA dla PITX2C. Inne mechanizmy tworzą jeszcze więcej form białka PITX214. Okazuje się, że komórki muszą wyprodukować odpowiednią „wersję” PITX2 we właściwym miejscu i we właściwym czasie, jeśli organizm – którego są częścią – ma się normalnie rozwijać.
Skąd zatem komórka „wie”, kiedy należy wytworzyć tę, a nie inną formę białka? Odpowiedź znajdujemy w tym, co uprzednio zostało uznane za „śmieciowe” DNA, które teraz ukazuje całą dynamikę funkcjonowania genomów, której wcześniej nie dostrzegano. Wydaje się, że złożone systemy kontrolujące składanie eksonów obejmują sekwencje zajmujące co najmniej jedną trzecią genomu ludzkiego15, co znacznie przekracza 3% ludzkiego genomu, który jeszcze kilka lat temu uważany był za jedyną funkcjonalną, kodującą część ludzkiego materiału genetycznego. Wyłaniający się obraz DNA pokazuje, że w rzeczywistości przechowuje on ogromne ilości informacji, z których znaczną część pierwsi naukowcy pominęli w prowadzonych badaniach. Z dużą dozą prawdopodobieństwa można stwierdzić, że jeszcze wiele pozostaje do odkrycia w kwestii funkcjonowania genomów.
Wnioski
W wyborze DNA jako nośnika do przechowywania informacji genetycznej znajduje się piękno, złożoność, elegancja i skuteczność, a sama informacja jest niesamowita. Część tego, co wiemy o genomach dobrze pasuje do tezy o wspólnym pochodzeniu i ewolucji darwinowskiej, ale jako całość, dowody są bardziej spójne z biblijnym światopoglądem, w którym Projektant, Bóg, odpowiada za wybór DNA jako materiału genetycznego, ogromne ilości przechowywanych w nim informacji oraz przemyślany układ tej informacji w genomach.
Kiedy Bóg Stwórca napisał 10 Przykazań16, uczynił to na trwałym kamiennym nośniku. Ale kiedy zapisał grzechy samolubnych uczonych w piśmie i faryzeuszy, napisał je na ziemi, gdzie Jego słowa mogły być szybko zatarte17. Bóg Biblii pokazał, że potrafi wybrać odpowiednie nośniki do zapisu określonej informacji i nie powinien nas dziwić fakt, że również dla żywych istot wybrał najodpowiedniejszy nośnik, jakim jest DNA, w celu zapisania informacji genetycznej, a przechowywana w DNA informacja jest przemyślana i niesamowita. Każda osoba, każde stworzenie, każda roślina – każdy żywy organizm – jest znakomitym magazynem informacji genetycznej zakodowanej w DNA, informacji o wiele bardziej wykwintnej i głęboko znaczącej niż cokolwiek napisane przez Williama Szekspira lub jakiegokolwiek innego autora. Chrześcijanie mają dobry powód, by wierzyć, że jesteśmy „zadziwiająco i cudownie stworzeni”18 i że Bóg, który stworzył nas wraz ze wszystkimi innymi rzeczami, jest godny naszego uwielbienia.
Przypisy
- Green R.E., Krause J., Briggs A.W. i in. (2010), “A Draft Sequence of the Neandertal Genome”, “Science”,328(5979):710-722; doi: 10.1126/science.1188021
- Miller W., Drautz D.I., Ratan A., i in. (2008), “Sequencing the nuclear genome of the extinct woolly mammoth”, “Nature”,456:387-390; doi:10.1038/nature07446
- Otrzymujemy pełny zestaw ludzkich chromosomów od każdego rodzica: 23 od naszej matki i 23 od naszego ojca, w sumie 46. Większość komórek ludzkich ma wszystkie 46 chromosomów w jądrze.
- Bianconi E., Piovesan A., Facchin F., Beraudi A., Casadei R., Frabetti F., Vitale L., Pelleri M.C., Tassani S., Piva F., Perez-Amodio S., Strippoli P., Canaider S. (2013), “An estimation of the number of cells in the human body”, “Annals of Human Biology”, 40(6):463-71; doi: 10.3109/03014460.2013.807878
- Pellicer J., Fay M.F., Leitch A.J. (2010), “The largest eukaryotic genome of them all?”, “Botanical Journal of the Linnean Society”,164(1):10–15; doi: 10.1111/j.1095-8339.2010.01072.x
- Watson J.D., Crick F.H.C. (1953), “A structure for deoxyribose nucleic acid”, “Nature”,171:737-738.
- Należy zauważyć, że z powodu konwencji zwykle stosowanych przez biologów molekularnych, sekwencje te nie byłyby zapisane dokładnie w ten sposób.
- Darwin C.R. (1859), “On the origin of species by means of natural selection, or the preservation of favoured races in the struggle for life”, Wyd. 1, John Murray, London, s. 189.
- Księga Rodzaju 1,31
- Makalowski W. (2003), “Not junk after all”, “Science”,300:5623.
- Ohno S. (1972), “So much „junk” DNA in our genome” [w:] H.H. Smith (red.) “Evolution of genetic systems”, Brookhaven symposia in biology 23, Gordon and Breach, New York, s. 366-70.
- Clamp M., Fry B., Kamal M., Xie X., Cuff J., Lin M.F., Kellis M., Lindblad-Toh K., Lander E.S. (2007), “Distinguishing protein-coding and noncoding genes in the human genome”, “Proceedings of the National Academy of SciencesUSA”, 104:19428–19433.
- Gage P.J., Suh H., Camper S.A. (1999), “The bicoid-related Pitx gene family in development”, “Mammalian Genome”, 10(2):197-200.
- Lamba P., Hjalt T.A., Bernard D.J. (2008), “Novel forms of Paired-like homeodomain transcription factor 2 (PITX2): Generation by alternative translation initiation and mRNA splicing”, “BMC Molecular Biology”, 9:31.
- Zhang C., Li W.-H., Krainer A.R., Zhang M.Q. (2008), “RNA landscape of evolution for optimal exon and intron discrimination”, “Proceedings of the National Academy of Sciences USA”, 105(15):5797–5802.
- Księga Wyjścia 31,18; Księga Powtórzonego Prawa 9,10
- Ewangelia Jana 8,7-8
- Psalm 139,14
